
models.wrappers.ldamallet – Latent Dirichlet Allocation via Mallet¶
Python wrapper for Latent Dirichlet Allocation (LDA) from MALLET, the Java topic modelling toolkit
This module allows both LDA model estimation from a training corpus and inference of topic distribution on new, unseen documents, using an (optimized version of) collapsed gibbs sampling from MALLET.
Notes
MALLET’s LDA training requires 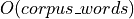 of memory, keeping the entire corpus in RAM.
If you find yourself running out of memory, either decrease the workers constructor parameter,
or use
of memory, keeping the entire corpus in RAM.
If you find yourself running out of memory, either decrease the workers constructor parameter,
or use gensim.models.ldamodel.LdaModel or gensim.models.ldamulticore.LdaMulticore
which needs only 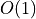 memory.
The wrapped model can NOT be updated with new documents for online training – use
memory.
The wrapped model can NOT be updated with new documents for online training – use
LdaModel or LdaMulticore for that.
Installation¶
Use official guide or this one
sudo apt-get install default-jdk
sudo apt-get install ant
git clone git@github.com:mimno/Mallet.git
cd Mallet/
ant
Examples
>>> from gensim.test.utils import common_corpus, common_dictionary
>>> from gensim.models.wrappers import LdaMallet
>>>
>>> path_to_mallet_binary = "/path/to/mallet/binary"
>>> model = LdaMallet(path_to_mallet_binary, corpus=common_corpus, num_topics=20, id2word=common_dictionary)
>>> vector = model[common_corpus[0]] # LDA topics of a documents
-
class
gensim.models.wrappers.ldamallet.LdaMallet(mallet_path, corpus=None, num_topics=100, alpha=50, id2word=None, workers=4, prefix=None, optimize_interval=0, iterations=1000, topic_threshold=0.0, random_seed=0)¶ Bases:
gensim.utils.SaveLoad,gensim.models.basemodel.BaseTopicModelPython wrapper for LDA using MALLET.
Communication between MALLET and Python takes place by passing around data files on disk and calling Java with subprocess.call().
Warning
This is only python wrapper for MALLET LDA, you need to install original implementation first and pass the path to binary to
mallet_path.- Parameters
mallet_path (str) – Path to the mallet binary, e.g. /home/username/mallet-2.0.7/bin/mallet.
corpus (iterable of iterable of (int, int), optional) – Collection of texts in BoW format.
num_topics (int, optional) – Number of topics.
alpha (int, optional) – Alpha parameter of LDA.
id2word (
Dictionary, optional) – Mapping between tokens ids and words from corpus, if not specified - will be inferred from corpus.workers (int, optional) – Number of threads that will be used for training.
prefix (str, optional) – Prefix for produced temporary files.
optimize_interval (int, optional) – Optimize hyperparameters every optimize_interval iterations (sometimes leads to Java exception 0 to switch off hyperparameter optimization).
iterations (int, optional) – Number of training iterations.
topic_threshold (float, optional) – Threshold of the probability above which we consider a topic.
random_seed (int, optional) – Random seed to ensure consistent results, if 0 - use system clock.
-
convert_input(corpus, infer=False, serialize_corpus=True)¶ Convert corpus to Mallet format and save it to a temporary text file.
- Parameters
corpus (iterable of iterable of (int, int)) – Collection of texts in BoW format.
infer (bool, optional) –
…
serialize_corpus (bool, optional) –
…
-
corpus2mallet(corpus, file_like)¶ Convert corpus to Mallet format and write it to file_like descriptor.
Format
document id[SPACE]label (not used)[SPACE]whitespace delimited utf8-encoded tokens[NEWLINE]
- Parameters
corpus (iterable of iterable of (int, int)) – Collection of texts in BoW format.
file_like (file-like object) – Opened file.
-
fcorpusmallet()¶ Get path to corpus.mallet file.
- Returns
Path to corpus.mallet file.
- Return type
str
-
fcorpustxt()¶ Get path to corpus text file.
- Returns
Path to corpus text file.
- Return type
str
-
fdoctopics()¶ Get path to document topic text file.
- Returns
Path to document topic text file.
- Return type
str
-
finferencer()¶ Get path to inferencer.mallet file.
- Returns
Path to inferencer.mallet file.
- Return type
str
-
fstate()¶ Get path to temporary file.
- Returns
Path to file.
- Return type
str
-
ftopickeys()¶ Get path to topic keys text file.
- Returns
Path to topic keys text file.
- Return type
str
-
fwordweights()¶ Get path to word weight file.
- Returns
Path to word weight file.
- Return type
str
-
get_topics()¶ Get topics X words matrix.
- Returns
Topics X words matrix, shape num_topics x vocabulary_size.
- Return type
numpy.ndarray
-
get_version(direc_path)¶ “Get the version of Mallet.
- Parameters
direc_path (str) – Path to mallet archive.
- Returns
Version of mallet.
- Return type
str
-
classmethod
load(*args, **kwargs)¶ Load a previously saved LdaMallet class. Handles backwards compatibility from older LdaMallet versions which did not use random_seed parameter.
-
load_document_topics()¶ Load document topics from
gensim.models.wrappers.ldamallet.LdaMallet.fdoctopics()file. Shortcut forgensim.models.wrappers.ldamallet.LdaMallet.read_doctopics().- Returns
Sequence of LDA vectors for documents.
- Return type
iterator of list of (int, float)
-
load_word_topics()¶ Load words X topics matrix from
gensim.models.wrappers.ldamallet.LdaMallet.fstate()file.- Returns
Matrix words X topics.
- Return type
numpy.ndarray
-
print_topic(topicno, topn=10)¶ Get a single topic as a formatted string.
- Parameters
topicno (int) – Topic id.
topn (int) – Number of words from topic that will be used.
- Returns
String representation of topic, like ‘-0.340 * “category” + 0.298 * “$M$” + 0.183 * “algebra” + … ‘.
- Return type
str
-
print_topics(num_topics=20, num_words=10)¶ Get the most significant topics (alias for show_topics() method).
- Parameters
num_topics (int, optional) – The number of topics to be selected, if -1 - all topics will be in result (ordered by significance).
num_words (int, optional) – The number of words to be included per topics (ordered by significance).
- Returns
Sequence with (topic_id, [(word, value), … ]).
- Return type
list of (int, list of (str, float))
-
read_doctopics(fname, eps=1e-06, renorm=True)¶ Get document topic vectors from MALLET’s “doc-topics” format, as sparse gensim vectors.
- Parameters
fname (str) – Path to input file with document topics.
eps (float, optional) – Threshold for probabilities.
renorm (bool, optional) – If True - explicitly re-normalize distribution.
- Raises
RuntimeError – If any line in invalid format.
- Yields
list of (int, float) – LDA vectors for document.
-
save(fname_or_handle, separately=None, sep_limit=10485760, ignore=frozenset({}), pickle_protocol=2)¶ Save the object to a file.
- Parameters
fname_or_handle (str or file-like) – Path to output file or already opened file-like object. If the object is a file handle, no special array handling will be performed, all attributes will be saved to the same file.
separately (list of str or None, optional) –
If None, automatically detect large numpy/scipy.sparse arrays in the object being stored, and store them into separate files. This prevent memory errors for large objects, and also allows memory-mapping the large arrays for efficient loading and sharing the large arrays in RAM between multiple processes.
If list of str: store these attributes into separate files. The automated size check is not performed in this case.
sep_limit (int, optional) – Don’t store arrays smaller than this separately. In bytes.
ignore (frozenset of str, optional) – Attributes that shouldn’t be stored at all.
pickle_protocol (int, optional) – Protocol number for pickle.
See also
load()Load object from file.
-
show_topic(topicid, topn=10, num_words=None)¶ Get num_words most probable words for the given topicid.
- Parameters
topicid (int) – Id of topic.
topn (int, optional) – Top number of topics that you’ll receive.
num_words (int, optional) – DEPRECATED PARAMETER, use topn instead.
- Returns
Sequence of probable words, as a list of (word, word_probability) for topicid topic.
- Return type
list of (str, float)
-
show_topics(num_topics=10, num_words=10, log=False, formatted=True)¶ Get the num_words most probable words for num_topics number of topics.
- Parameters
num_topics (int, optional) – Number of topics to return, set -1 to get all topics.
num_words (int, optional) – Number of words.
log (bool, optional) – If True - write topic with logging too, used for debug proposes.
formatted (bool, optional) – If True - return the topics as a list of strings, otherwise as lists of (weight, word) pairs.
- Returns
list of str – Topics as a list of strings (if formatted=True) OR
list of (float, str) – Topics as list of (weight, word) pairs (if formatted=False)
-
train(corpus)¶ Train Mallet LDA.
- Parameters
corpus (iterable of iterable of (int, int)) – Corpus in BoW format