
corpora.indexedcorpus – Random access to corpus documents¶
Base Indexed Corpus class.
-
class
gensim.corpora.indexedcorpus.IndexedCorpus(fname, index_fname=None)¶ Bases:
gensim.interfaces.CorpusABCIndexed corpus is a mechanism for random-accessing corpora.
While the standard corpus interface in gensim allows iterating over corpus, we’ll show it with
MmCorpus.>>> from gensim.corpora import MmCorpus >>> from gensim.test.utils import datapath >>> >>> corpus = MmCorpus(datapath('testcorpus.mm')) >>> for doc in corpus: ... pass
IndexedCorpusallows accessing the documents with index in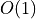 look-up time.
look-up time.>>> document_index = 3 >>> doc = corpus[document_index]
Notes
This functionality is achieved by storing an extra file (by default named the same as the fname.index) that stores the byte offset of the beginning of each document.
- Parameters
fname (str) – Path to corpus.
index_fname (str, optional) – Path to index, if not provided - used fname.index.
-
classmethod
load(fname, mmap=None)¶ Load an object previously saved using
save()from a file.- Parameters
fname (str) – Path to file that contains needed object.
mmap (str, optional) – Memory-map option. If the object was saved with large arrays stored separately, you can load these arrays via mmap (shared memory) using mmap=’r’. If the file being loaded is compressed (either ‘.gz’ or ‘.bz2’), then `mmap=None must be set.
See also
save()Save object to file.
- Returns
Object loaded from fname.
- Return type
object
- Raises
AttributeError – When called on an object instance instead of class (this is a class method).
-
save(*args, **kwargs)¶ Saves corpus in-memory state.
Warning
This save only the “state” of a corpus class, not the corpus data!
For saving data use the serialize method of the output format you’d like to use (e.g.
gensim.corpora.mmcorpus.MmCorpus.serialize()).
-
static
save_corpus(fname, corpus, id2word=None, metadata=False)¶ Save corpus to disk.
Some formats support saving the dictionary (feature_id -> word mapping), which can be provided by the optional id2word parameter.
Notes
Some corpora also support random access via document indexing, so that the documents on disk can be accessed in O(1) time (see the
gensim.corpora.indexedcorpus.IndexedCorpusbase class).In this case,
save_corpus()is automatically called internally byserialize(), which doessave_corpus()plus saves the index at the same time.Calling
serialize() is preferred to calling :meth:`gensim.interfaces.CorpusABC.save_corpus().- Parameters
fname (str) – Path to output file.
corpus (iterable of list of (int, number)) – Corpus in BoW format.
id2word (
Dictionary, optional) – Dictionary of corpus.metadata (bool, optional) – Write additional metadata to a separate too?
-
classmethod
serialize(fname, corpus, id2word=None, index_fname=None, progress_cnt=None, labels=None, metadata=False)¶ Serialize corpus with offset metadata, allows to use direct indexes after loading.
- Parameters
fname (str) – Path to output file.
corpus (iterable of iterable of (int, float)) – Corpus in BoW format.
id2word (dict of (str, str), optional) – Mapping id -> word.
index_fname (str, optional) – Where to save resulting index, if None - store index to fname.index.
progress_cnt (int, optional) – Number of documents after which progress info is printed.
labels (bool, optional) – If True - ignore first column (class labels).
metadata (bool, optional) – If True - ensure that serialize will write out article titles to a pickle file.
Examples
>>> from gensim.corpora import MmCorpus >>> from gensim.test.utils import get_tmpfile >>> >>> corpus = [[(1, 0.3), (2, 0.1)], [(1, 0.1)], [(2, 0.3)]] >>> output_fname = get_tmpfile("test.mm") >>> >>> MmCorpus.serialize(output_fname, corpus) >>> mm = MmCorpus(output_fname) # `mm` document stream now has random access >>> print(mm[1]) # retrieve document no. 42, etc. [(1, 0.1)]