
models.phrases – Phrase (collocation) detection¶
Automatically detect common phrases – aka multi-word expressions, word n-gram collocations – from a stream of sentences.
Inspired by:
Mikolov, et. al: “Distributed Representations of Words and Phrases and their Compositionality”
“Normalized (Pointwise) Mutual Information in Colocation Extraction” by Gerlof Bouma
Examples
>>> from gensim.test.utils import datapath
>>> from gensim.models.word2vec import Text8Corpus
>>> from gensim.models.phrases import Phrases, Phraser
>>>
>>> # Load training data.
>>> sentences = Text8Corpus(datapath('testcorpus.txt'))
>>> # The training corpus must be a sequence (stream, generator) of sentences,
>>> # with each sentence a list of tokens:
>>> print(list(sentences)[0][:10])
['computer', 'human', 'interface', 'computer', 'response', 'survey', 'system', 'time', 'user', 'interface']
>>>
>>> # Train a toy bigram model.
>>> phrases = Phrases(sentences, min_count=1, threshold=1)
>>> # Apply the trained phrases model to a new, unseen sentence.
>>> phrases[['trees', 'graph', 'minors']]
['trees_graph', 'minors']
>>> # The toy model considered "trees graph" a single phrase => joined the two
>>> # tokens into a single token, `trees_graph`.
>>>
>>> # Update the model with two new sentences on the fly.
>>> phrases.add_vocab([["hello", "world"], ["meow"]])
>>>
>>> # Export the trained model = use less RAM, faster processing. Model updates no longer possible.
>>> bigram = Phraser(phrases)
>>> bigram[['trees', 'graph', 'minors']] # apply the exported model to a sentence
['trees_graph', 'minors']
>>>
>>> # Apply the exported model to each sentence of a corpus:
>>> for sent in bigram[sentences]:
... pass
>>>
>>> # Save / load an exported collocation model.
>>> bigram.save("/tmp/my_bigram_model.pkl")
>>> bigram_reloaded = Phraser.load("/tmp/my_bigram_model.pkl")
>>> bigram_reloaded[['trees', 'graph', 'minors']] # apply the exported model to a sentence
['trees_graph', 'minors']
-
class
gensim.models.phrases.Phraser(phrases_model)¶ Bases:
gensim.models.phrases.SentenceAnalyzer,gensim.models.phrases.PhrasesTransformationMinimal state & functionality exported from
Phrases.The goal of this class is to cut down memory consumption of Phrases, by discarding model state not strictly needed for the bigram detection task.
Use this instead of Phrases if you do not need to update the bigram statistics with new documents any more.
- Parameters
phrases_model (
Phrases) – Trained phrases instance.
Notes
After the one-time initialization, a
Phraserwill be much smaller and somewhat faster than using the fullPhrasesmodel.Examples
>>> from gensim.test.utils import datapath >>> from gensim.models.word2vec import Text8Corpus >>> from gensim.models.phrases import Phrases, Phraser >>> >>> sentences = Text8Corpus(datapath('testcorpus.txt')) >>> phrases = Phrases(sentences, min_count=1, threshold=1) >>> >>> bigram = Phraser(phrases) >>> sent = [u'trees', u'graph', u'minors'] >>> print(bigram[sent]) [u'trees_graph', u'minors']
-
analyze_sentence(sentence, threshold, common_terms, scorer)¶ Analyze a sentence, detecting any bigrams that should be concatenated.
- Parameters
sentence (iterable of str) – Token sequence representing the sentence to be analyzed.
threshold (float) – The minimum score for a bigram to be taken into account.
common_terms (list of object) – List of common terms, they receive special treatment.
scorer (function) – Scorer function, as given to
Phrases. Seenpmi_scorer()andoriginal_scorer().
- Yields
(str, score) – If bi-gram detected, a tuple where the first element is a detect bigram, second its score. Otherwise, the first tuple element is a single word and second is None.
-
classmethod
load(*args, **kwargs)¶ Load a previously saved
Phrases/Phraserclass. Handles backwards compatibility from olderPhrases/Phraserversions which did not support pluggable scoring functions.
-
pseudocorpus(phrases_model)¶ Alias for
gensim.models.phrases.pseudocorpus().- Parameters
phrases_model (
Phrases) – Phrases instance.- Returns
Generator with phrases.
- Return type
generator
-
save(fname_or_handle, separately=None, sep_limit=10485760, ignore=frozenset({}), pickle_protocol=2)¶ Save the object to a file.
- Parameters
fname_or_handle (str or file-like) – Path to output file or already opened file-like object. If the object is a file handle, no special array handling will be performed, all attributes will be saved to the same file.
separately (list of str or None, optional) –
If None, automatically detect large numpy/scipy.sparse arrays in the object being stored, and store them into separate files. This prevent memory errors for large objects, and also allows memory-mapping the large arrays for efficient loading and sharing the large arrays in RAM between multiple processes.
If list of str: store these attributes into separate files. The automated size check is not performed in this case.
sep_limit (int, optional) – Don’t store arrays smaller than this separately. In bytes.
ignore (frozenset of str, optional) – Attributes that shouldn’t be stored at all.
pickle_protocol (int, optional) – Protocol number for pickle.
See also
load()Load object from file.
-
score_item(worda, wordb, components, scorer)¶ Score a bigram.
- Parameters
worda (str) – First word for comparison.
wordb (str) – Second word for comparison.
components (generator) – Contain phrases.
scorer ({'default', 'npmi'}) – NOT USED.
- Returns
Score for given bi-gram, if bi-gram not presented in dictionary - return -1.
- Return type
float
-
class
gensim.models.phrases.Phrases(sentences=None, min_count=5, threshold=10.0, max_vocab_size=40000000, delimiter=b'_', progress_per=10000, scoring='default', common_terms=frozenset({}))¶ Bases:
gensim.models.phrases.SentenceAnalyzer,gensim.models.phrases.PhrasesTransformationDetect phrases based on collocation counts.
- Parameters
sentences (iterable of list of str, optional) – The sentences iterable can be simply a list, but for larger corpora, consider a generator that streams the sentences directly from disk/network, See
BrownCorpus,Text8CorpusorLineSentencefor such examples.min_count (float, optional) – Ignore all words and bigrams with total collected count lower than this value.
threshold (float, optional) – Represent a score threshold for forming the phrases (higher means fewer phrases). A phrase of words a followed by b is accepted if the score of the phrase is greater than threshold. Heavily depends on concrete scoring-function, see the scoring parameter.
max_vocab_size (int, optional) – Maximum size (number of tokens) of the vocabulary. Used to control pruning of less common words, to keep memory under control. The default of 40M needs about 3.6GB of RAM. Increase/decrease max_vocab_size depending on how much available memory you have.
delimiter (str, optional) – Glue character used to join collocation tokens, should be a byte string (e.g. b’_’).
scoring ({'default', 'npmi', function}, optional) –
Specify how potential phrases are scored. scoring can be set with either a string that refers to a built-in scoring function, or with a function with the expected parameter names. Two built-in scoring functions are available by setting scoring to a string:
”default” -
original_scorer().”npmi” -
npmi_scorer().
common_terms (set of str, optional) – List of “stop words” that won’t affect frequency count of expressions containing them. Allow to detect expressions like “bank_of_america” or “eye_of_the_beholder”.
Notes
‘npmi’ is more robust when dealing with common words that form part of common bigrams, and ranges from -1 to 1, but is slower to calculate than the default. The default is the PMI-like scoring as described by Mikolov, et. al: “Distributed Representations of Words and Phrases and their Compositionality”.
To use a custom scoring function, pass in a function with the following signature:
worda_count - number of corpus occurrences in sentences of the first token in the bigram being scored
wordb_count - number of corpus occurrences in sentences of the second token in the bigram being scored
bigram_count - number of occurrences in sentences of the whole bigram
len_vocab - the number of unique tokens in sentences
min_count - the min_count setting of the Phrases class
corpus_word_count - the total number of tokens (non-unique) in sentences
The scoring function must accept all these parameters, even if it doesn’t use them in its scoring. The scoring function must be pickleable.
-
add_vocab(sentences)¶ Update model with new sentences.
- Parameters
sentences (iterable of list of str) – Text corpus.
Example
>>> from gensim.test.utils import datapath >>> from gensim.models.word2vec import Text8Corpus >>> from gensim.models.phrases import Phrases >>> # Create corpus and use it for phrase detector >>> sentences = Text8Corpus(datapath('testcorpus.txt')) >>> phrases = Phrases(sentences) # train model >>> assert len(phrases.vocab) == 37 >>> >>> more_sentences = [ ... [u'the', u'mayor', u'of', u'new', u'york', u'was', u'there'], ... [u'machine', u'learning', u'can', u'be', u'new', u'york', u'sometimes'] ... ] >>> >>> phrases.add_vocab(more_sentences) # add new sentences to model >>> assert len(phrases.vocab) == 60
-
analyze_sentence(sentence, threshold, common_terms, scorer)¶ Analyze a sentence, detecting any bigrams that should be concatenated.
- Parameters
sentence (iterable of str) – Token sequence representing the sentence to be analyzed.
threshold (float) – The minimum score for a bigram to be taken into account.
common_terms (list of object) – List of common terms, they receive special treatment.
scorer (function) – Scorer function, as given to
Phrases. Seenpmi_scorer()andoriginal_scorer().
- Yields
(str, score) – If bi-gram detected, a tuple where the first element is a detect bigram, second its score. Otherwise, the first tuple element is a single word and second is None.
-
export_phrases(sentences, out_delimiter=b' ', as_tuples=False)¶ Get all phrases that appear in ‘sentences’ that pass the bigram threshold.
- Parameters
sentences (iterable of list of str) – Text corpus.
out_delimiter (str, optional) – Delimiter used to “glue” together words that form a bigram phrase.
as_tuples (bool, optional) – Yield (tuple(words), score) instead of (out_delimiter.join(words), score)?
- Yields
((str, str), float) **or* (str, float)* – Phrases detected in sentences. Return type depends on the as_tuples parameter.
Example
>>> from gensim.test.utils import datapath >>> from gensim.models.word2vec import Text8Corpus >>> from gensim.models.phrases import Phrases >>> >>> sentences = Text8Corpus(datapath('testcorpus.txt')) >>> phrases = Phrases(sentences, min_count=1, threshold=0.1) >>> >>> for phrase, score in phrases.export_phrases(sentences): ... pass
-
static
learn_vocab(sentences, max_vocab_size, delimiter=b'_', progress_per=10000, common_terms=frozenset({}))¶ Collect unigram/bigram counts from the sentences iterable.
- Parameters
sentences (iterable of list of str) – The sentences iterable can be simply a list, but for larger corpora, consider a generator that streams the sentences directly from disk/network, See
BrownCorpus,Text8CorpusorLineSentencefor such examples.max_vocab_size (int) – Maximum size (number of tokens) of the vocabulary. Used to control pruning of less common words, to keep memory under control. The default of 40M needs about 3.6GB of RAM. Increase/decrease max_vocab_size depending on how much available memory you have.
delimiter (str, optional) – Glue character used to join collocation tokens, should be a byte string (e.g. b’_’).
progress_per (int) – Write logs every progress_per sentence.
common_terms (set of str, optional) – List of “stop words” that won’t affect frequency count of expressions containing them. Allow to detect expressions like “bank_of_america” or “eye_of_the_beholder”.
- Returns
Number of pruned words, counters for each word/bi-gram and total number of words.
- Return type
(int, dict of (str, int), int)
Example
>>> from gensim.test.utils import datapath >>> from gensim.models.word2vec import Text8Corpus >>> from gensim.models.phrases import Phrases >>> >>> sentences = Text8Corpus(datapath('testcorpus.txt')) >>> pruned_words, counters, total_words = Phrases.learn_vocab(sentences, 100) >>> (pruned_words, total_words) (1, 29) >>> counters['computer'] 2 >>> counters['response_time'] 1
-
classmethod
load(*args, **kwargs)¶ Load a previously saved Phrases class. Handles backwards compatibility from older Phrases versions which did not support pluggable scoring functions.
-
save(fname_or_handle, separately=None, sep_limit=10485760, ignore=frozenset({}), pickle_protocol=2)¶ Save the object to a file.
- Parameters
fname_or_handle (str or file-like) – Path to output file or already opened file-like object. If the object is a file handle, no special array handling will be performed, all attributes will be saved to the same file.
separately (list of str or None, optional) –
If None, automatically detect large numpy/scipy.sparse arrays in the object being stored, and store them into separate files. This prevent memory errors for large objects, and also allows memory-mapping the large arrays for efficient loading and sharing the large arrays in RAM between multiple processes.
If list of str: store these attributes into separate files. The automated size check is not performed in this case.
sep_limit (int, optional) – Don’t store arrays smaller than this separately. In bytes.
ignore (frozenset of str, optional) – Attributes that shouldn’t be stored at all.
pickle_protocol (int, optional) – Protocol number for pickle.
See also
load()Load object from file.
-
score_item(worda, wordb, components, scorer)¶ Get bi-gram score statistics.
- Parameters
worda (str) – First word of bi-gram.
wordb (str) – Second word of bi-gram.
components (generator) – Contain all phrases.
scorer (function) – Scorer function, as given to
Phrases. Seenpmi_scorer()andoriginal_scorer().
- Returns
Score for given bi-gram. If bi-gram not present in dictionary - return -1.
- Return type
float
-
class
gensim.models.phrases.PhrasesTransformation¶ Bases:
gensim.interfaces.TransformationABCBase util class for
PhrasesandPhraser.-
classmethod
load(*args, **kwargs)¶ Load a previously saved
Phrases/Phraserclass. Handles backwards compatibility from olderPhrases/Phraserversions which did not support pluggable scoring functions.
-
save(fname_or_handle, separately=None, sep_limit=10485760, ignore=frozenset({}), pickle_protocol=2)¶ Save the object to a file.
- Parameters
fname_or_handle (str or file-like) – Path to output file or already opened file-like object. If the object is a file handle, no special array handling will be performed, all attributes will be saved to the same file.
separately (list of str or None, optional) –
If None, automatically detect large numpy/scipy.sparse arrays in the object being stored, and store them into separate files. This prevent memory errors for large objects, and also allows memory-mapping the large arrays for efficient loading and sharing the large arrays in RAM between multiple processes.
If list of str: store these attributes into separate files. The automated size check is not performed in this case.
sep_limit (int, optional) – Don’t store arrays smaller than this separately. In bytes.
ignore (frozenset of str, optional) – Attributes that shouldn’t be stored at all.
pickle_protocol (int, optional) – Protocol number for pickle.
See also
load()Load object from file.
-
classmethod
-
class
gensim.models.phrases.SentenceAnalyzer¶ Bases:
objectBase util class for
PhrasesandPhraser.-
analyze_sentence(sentence, threshold, common_terms, scorer)¶ Analyze a sentence, detecting any bigrams that should be concatenated.
- Parameters
sentence (iterable of str) – Token sequence representing the sentence to be analyzed.
threshold (float) – The minimum score for a bigram to be taken into account.
common_terms (list of object) – List of common terms, they receive special treatment.
scorer (function) – Scorer function, as given to
Phrases. Seenpmi_scorer()andoriginal_scorer().
- Yields
(str, score) – If bi-gram detected, a tuple where the first element is a detect bigram, second its score. Otherwise, the first tuple element is a single word and second is None.
-
score_item(worda, wordb, components, scorer)¶ Get bi-gram score statistics.
- Parameters
worda (str) – First word of bi-gram.
wordb (str) – Second word of bi-gram.
components (generator) – Contain all phrases.
scorer (function) – Scorer function, as given to
Phrases. Seenpmi_scorer()andoriginal_scorer().
- Returns
Score for given bi-gram. If bi-gram not present in dictionary - return -1.
- Return type
float
-
-
gensim.models.phrases.npmi_scorer(worda_count, wordb_count, bigram_count, len_vocab, min_count, corpus_word_count)¶ Calculation NPMI score based on “Normalized (Pointwise) Mutual Information in Colocation Extraction” by Gerlof Bouma.
- Parameters
worda_count (int) – Number of occurrences for first word.
wordb_count (int) – Number of occurrences for second word.
bigram_count (int) – Number of co-occurrences for phrase “worda_wordb”.
len_vocab (int) – Not used.
min_count (int) – Ignore all bigrams with total collected count lower than this value.
corpus_word_count (int) – Total number of words in the corpus.
- Returns
Score for given bi-gram, in the range -1 to 1.
- Return type
float
Notes
Formula:
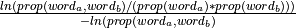 ,
where
,
where 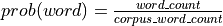
-
gensim.models.phrases.original_scorer(worda_count, wordb_count, bigram_count, len_vocab, min_count, corpus_word_count)¶ Bigram scoring function, based on the original Mikolov, et. al: “Distributed Representations of Words and Phrases and their Compositionality”.
- Parameters
worda_count (int) – Number of occurrences for first word.
wordb_count (int) – Number of occurrences for second word.
bigram_count (int) – Number of co-occurrences for phrase “worda_wordb”.
len_vocab (int) – Size of vocabulary.
min_count (int) – Minimum collocation count threshold.
corpus_word_count (int) – Not used in this particular scoring technique.
- Returns
Score for given bi-gram, greater than or equal to 0.
- Return type
float
Notes
Formula:
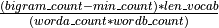 .
.
-
gensim.models.phrases.pseudocorpus(source_vocab, sep, common_terms=frozenset({}))¶ Feeds source_vocab’s compound keys back to it, to discover phrases.
- Parameters
source_vocab (iterable of list of str) – Tokens vocabulary.
sep (str) – Separator element.
common_terms (set, optional) – Immutable set of stopwords.
- Yields
list of str – Phrase.